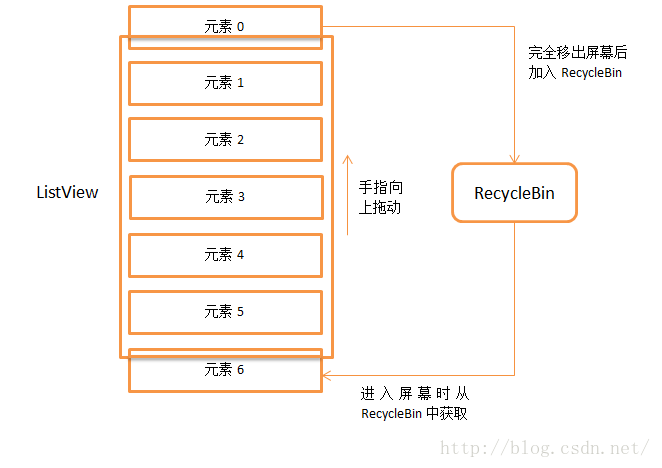
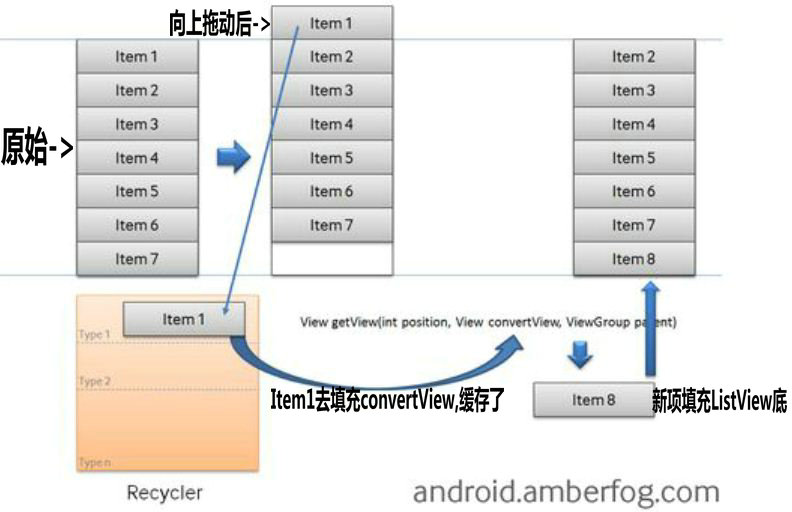
finalint measureHeightOfChildren(int widthMeasureSpec, int startPosition, int endPosition, finalint maxHeight, int disallowPartialChildPosition) {
final ListAdapter adapter = mAdapter; if (adapter == null) { return mListPadding.top + mListPadding.bottom; } int returnedHeight = mListPadding.top + mListPadding.bottom; ... View child; // onMeasure传递过来的endPosition==NO_POSITION,也就是-1,则令endPosition取数据源的adapter.getCount() - 1 endPosition = (endPosition == NO_POSITION) ? adapter.getCount() - 1 : endPosition; final AbsListView.RecycleBin recycleBin = mRecycler; finalboolean recyle = recycleOnMeasure(); finalboolean[] isScrap = mIsScrap; /* * 从起始位置0(onMeasure中传入的是0)开始,循环地创建ItemView,并累加ItemView的高度,当高度和超过onMeasure传递过来的maxHeight(其实是测量规格中的size)时,跳出循环 */ for (i = startPosition; i <= endPosition; ++i) { child = obtainView(i, isScrap);
measureScrapChild(child, i, widthMeasureSpec);
if (i > 0) { // 计算高度的时候还需将ItemView间的分隔距离考虑进来 returnedHeight += dividerHeight; }
// Recycle the view before we possibly return from the method if (recyle && recycleBin.shouldRecycleViewType( ((LayoutParams) child.getLayoutParams()).viewType)) { /* * 注意,这里addScrapView方法传入的第二个参数也就是position为-1, * 由于Layout过程中调用getScrapView方法时传入的position>=0, * 故position为-1的ScrapView都不会被回收,读懂这句话需要了解RecycleBin类,这里暂不深究。 */ recycleBin.addScrapView(child, -1); }
returnedHeight += child.getMeasuredHeight(); // 循环提前终止条件 if (returnedHeight >= maxHeight) { // 加上第i个的高度后returnedHeight已经超过了maxHeight,故高度探测应结束,说明最多只能容纳到第i个item return (disallowPartialChildPosition >= 0) // Disallowing is enabled (> -1) && (i > disallowPartialChildPosition) // We've past the min pos && (prevHeightWithoutPartialChild > 0) // We have a prev height && (returnedHeight != maxHeight) // 第i个Item不能显示完全,即超出容器 ? prevHeightWithoutPartialChild : maxHeight; }
if ((disallowPartialChildPosition >= 0) && (i >= disallowPartialChildPosition)) { prevHeightWithoutPartialChild = returnedHeight; } } return returnedHeight; }
A parent view may call measure() more than once on its children. For example, the parent may measure each child once with unspecified dimensions to find out how big they want to be, then call measure() on them again with actual numbers if the sum of all the children’s unconstrained sizes is too big or too small.
CMS收集器对CPU资源很敏感(面向并发设计的程序对CPU资源都非常敏感),在并发阶段,虽然不会导致用户线程停顿,但是会因为占用了一部分CPU资源而导致应用程序变慢,所以当CPU数量太少,就会导致用户程序执行速度直线下降,为了解决此问题,虚拟机提供“增量式并发收集器”(Increment Concurrent Mark Sweep/i-CMS),所用单CPU时的抢占式来模拟多任务机制思想,交替GC线程与用户线程,但是方法效果一般,所以已经不提倡用户使用